If you're in Infosec and you use Git, there's a good chance that you're just using it to clone and use the wealth of awesome open-source tools out there in the industry. If that's the case, rebasing probably isn't for you - it's just an added complication that won't add any real benefits.
If however, you collaborate on any development or contribute to any projects, then rebasing is a must-have tool in your arsenal that will make yours and everyone else's lives easier.
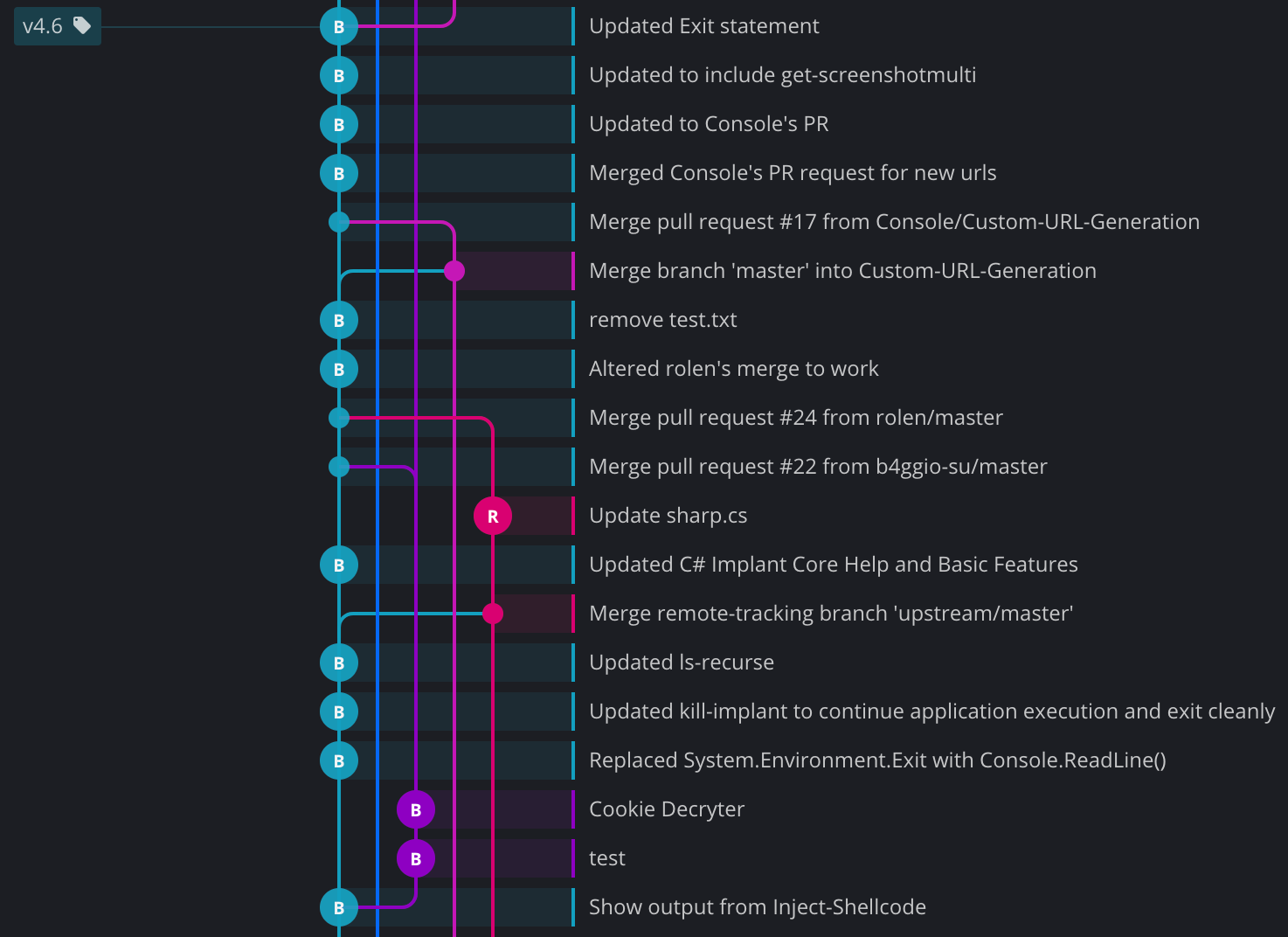
If your git history looks like this, a multicoloured, entangled, spaghetti-like mess that gives you PTSD flashbacks to Through the Fire and Flames on Guitar Hero, then you should know that for no extra effort it can instead look like this:
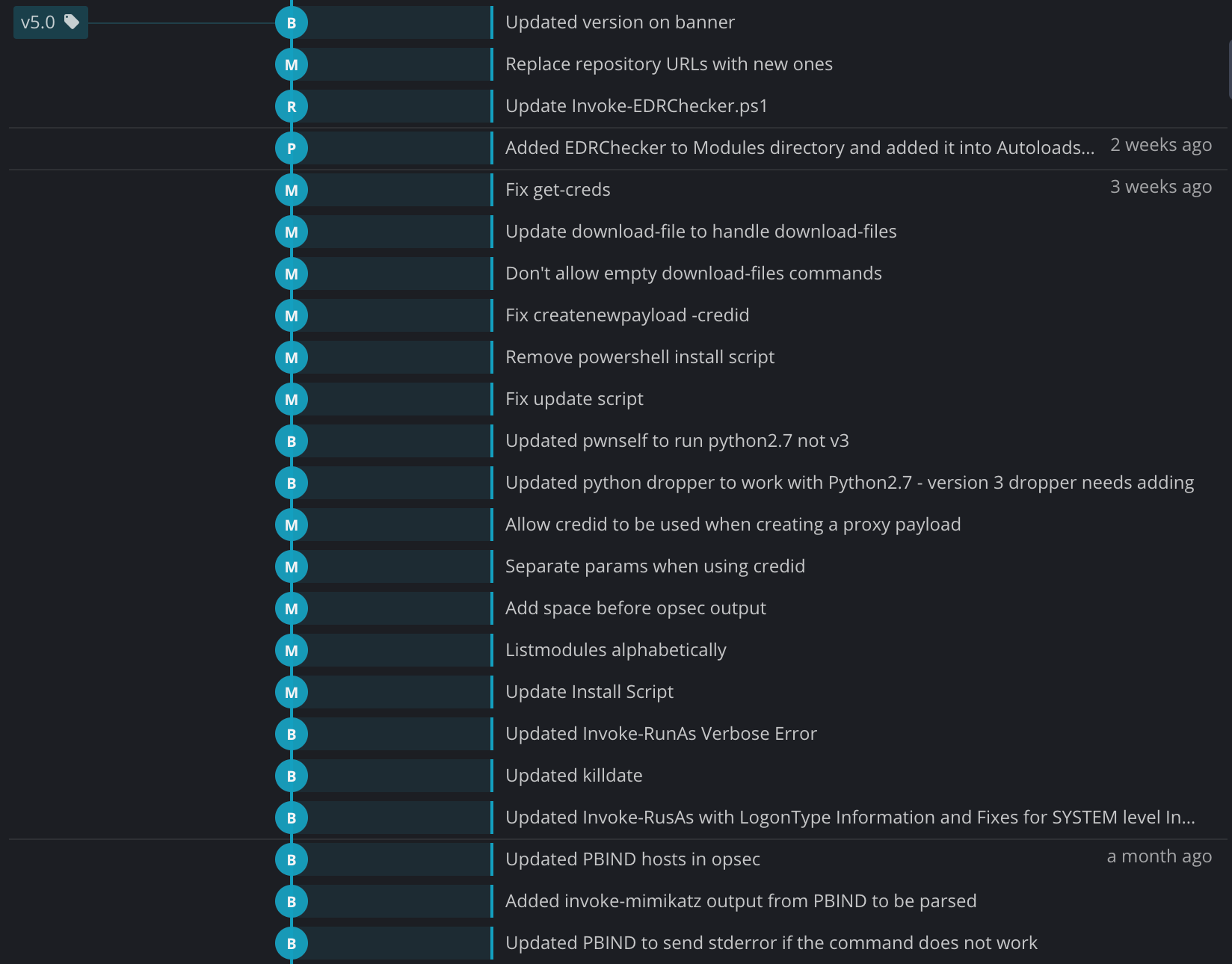
Read on to find out how.
Git Commits
The thing to know about git is that under the hood all a commit is is just the collection of differences between files that make up its particular change.
When you first create a git project you perform your initial commit which adds files to the repository, and every subsequent commit just applies changes to those files (or creates or deletes files) known as diffs (differences).
These commits are then chained together, and you can navigate up and down the chain to view the repository in prior states, navigating 'back through time'. All git is doing under the hood is applying or unapplying those differences as you navigate that chain.
To show what differences make up a particular commit, we can use the git show <commit hash> command.
For example, if we look at commit 8d95576 is repository, we can see that the commit message is printed, along with the author and date and so on. Under this there is the diff. It details that this should be applied to ./Help.py in the repository (the a and b just indicate the two versions of the file, before and after) and shows the affected lines, including what was deleted (the line prefixed with a -) and added (prefixed with a +), in this case, the version was updated from v4.8 to v5.0.
commit 8d95576a968e63d0c15bb4801add135ae64e9e12 (tag: v5.0) Author: benpturner <[email protected]> Date: Wed Nov 13 08:28:13 2019 +0000 Updated version on banner diff --git a/Help.py b/Help.py index dcf47ae..205e9eb 100644 --- a/Help.py +++ b/Help.py @@ -9,7 +9,7 @@ logopic = Colours.GREEN + r""" | | ( <_> )___ \| Y \ \ \____/ \\ |____| \____/____ >___| / \______ /\_______ \\ \/ \/ \/ \/ - =============== v4.8 www.PoshC2.co.uk ============= + =============== v5.0 www.PoshC2.co.uk ============= =========== %s =========== """ % commit
So that all works well when one individual is committing changes in a linear fashion, but what happens when a second changes the same line?
Git Merges
If two people are working on the same repository and they both perform one or more git commits, then how does git know what to do when they both try and push up their changes?
Well the first person to push is lucky, their commit goes straight up as the next commit on the branch. The second person however will try and push their change and it will get rejected and the server will say there's already another link in the commit chain at the place they are trying to add theirs.
#2 will then have to pull down #1's changes and merge them locally, then push up the new state, with the chain in the correct place.
During the git pull git will try and automatically smush the two states together, applying all of #2's changes on top of #1's work. If that works, great, if not #2 has to manually merge the changes into the correct state, whatever that may be.
After all this, the final merged state is committed into a 'merge commit' which encompasses all the changes that were added by #2, even if they were originally split into multiple commits. However the final git history shows both the original commits and the merge commit as the latter may have altered the original work while merging, but this appears to show duplicated work in the history as commits that are 'branched off', and when this happens with multiple users or multiple merges at a time, the history can get real messy real quick.
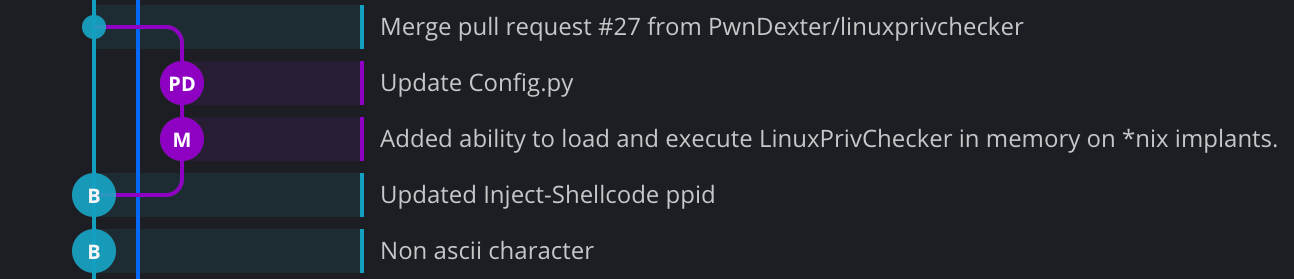
As you can see above in this simple case, the two commits that make up the merge (in purple) are shown as branched off as they were performed in a different 'timeline', and then a separate merge commit which encompasses all the changes from both of these commits is added to the main chain when those commits are merged. If the user encounters merge conflicts while merging these commits, they will have to resolve all the changes at once from all the commits, which can be hard to track and determine how each conflict should be resolved if the change is made up of multiple commits (here two).
All of this is the default way of doing things but it can end up being a bit of a nightmare trying to track down exactly what change came from where and who, which is why we're going to look at rebasing.
Git Rebasing
Rebasing is an alternative merging technique for git that involves taking the diffs in the commits that make up your change and just 'replaying' them on top of the head of the chain - you are changing the base of the branch to be the other branch (re-basing) and then applying any new commits on top.
So in the case of the version update commit above, if this commit was rebased onto master instead of merged, the change would just be applied on top of master as if it were a normal commit. If that would be the case anyway as no new commits were on the master branch, then the branch is instead just fast-forwarded to the most recent commit, as the work is already done.
If this is not the case and the first change is applied without any errors, then the next commit is applied on top of that one, and so on. The end result is that the states end up getting merged 'as if' they had happened all sequentially in the same 'timeline', as opposed to in parallel.
If there is an unresolvable conflict while applying a commit, then that conflict must still solved manually by the user, however these are done incrementally as the commits are applied one-by-one as opposed to all in one big blob. This makes it a lot easier to manage, as they will be smaller changes and you can compare the changes for the commits before and after to check state.
Ok so how?
The most common case where merges happen is when doing a git pull. You've made changes locally, someone else has made changes and pushed them to the server, and now you have to merge them.
To perform a rebase instead of a merge when doing a pull, simply add the --rebase option:
git pull --rebase
This will rewind your work to determine what is 'new', then apply those on top of the remote branch. For example, if we just had one commit called 'WIP':
First, rewinding head to replay your work on top of it...
Applying: WIP
You can also set up your git configuration to automatically rebase when pulling by running this command:
git config --global pull.rebase true
Then you can just enter git pull as usual.
If you want to rebase a branch locally (such as keeping a development branch up-to-date with master), you first check out the branch you want to change.
git checkout development
Then you use the git rebase command to rebase that branch on top of master, making it appear that all the new commits on development happened in a new timeline ahead of all commits on master
git rebase master
This command can include tags, hashes, references and so on such as:
git rebase origin/master
git rebase 583e3fb601cf1d6b683013e9c56dd22e59613975
If you want to abort your rebase you can run:
git rebase --abort
A word of warning
The only real 'gotcha' with this technique is that it alters the history of the branch you are rebasing as you are changing that branches base and then applying diffs on top of it.
The only case where this can be problematic is if the branch has already been pushed, as you cannot push a branch and change its history (caveat - keep reading) so your new push will be rejected. In general, only rebase local branches or local changes before pushing them up.
If you (and other contributors) commit locally and rebase when you pull instead of merging, then you two can have that slick, linear git history that makes things so much easier to view, in addition to simplifying merge conflicts and looking like a real boss.
If you do have to rebase a change that has already been pushed, then you can 'force push' with git push --force. Your branch which will overwrite the remote branch's history. This has the potential to lose work! - if someone else has pushed up another commit and you force push you can overwrite the history as if the change had never occurred, so be careful when doing so.
Summary
Rebasing is awesome and for no real extra effort it can make your life a lot easier. With a slight change to your configuration or commands you use, you too can adopt this better way of working.
For more git-fu, including how to get out of those 'oh crap' moments and how to avoid deleting and re-cloning repositories, check out the Git for Hackers series.